
LLM 竞赛 2025: 超越 Google 之路
LLM 竞赛 2025: 超越 Google 之路2023年6月,理想汽车推出了自研认知大模型“Mind GPT”,它以“理想同学”App的形式出现在理想汽车的车机中,支持通过自然语言交流、发送指令。2024年,Mind GPT升级到3.0,带来了行业领先的自然语言任务执行功能。
来自主题: AI资讯
10387 点击 2024-12-28 11:53
 搜索
搜索
2023年6月,理想汽车推出了自研认知大模型“Mind GPT”,它以“理想同学”App的形式出现在理想汽车的车机中,支持通过自然语言交流、发送指令。2024年,Mind GPT升级到3.0,带来了行业领先的自然语言任务执行功能。

最近,类 o1 模型的出现,验证了长思维链 (CoT) 在数学和编码等推理任务中的有效性。在长思考(long thought)的帮助下,LLM 倾向于探索、反思和自我改进推理过程,以获得更准确的答案。
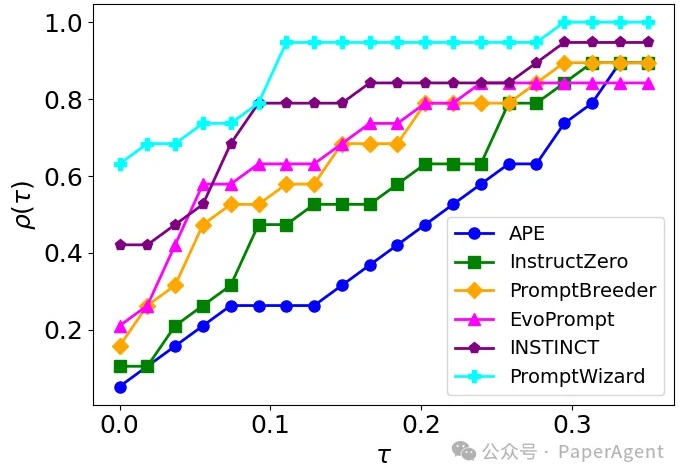
PromptWizard (PW) 旨在自动化和简化提示优化。它将 LLM 的迭代反馈与高效的探索和改进技术相结合,在几分钟内创建高效的prompts。
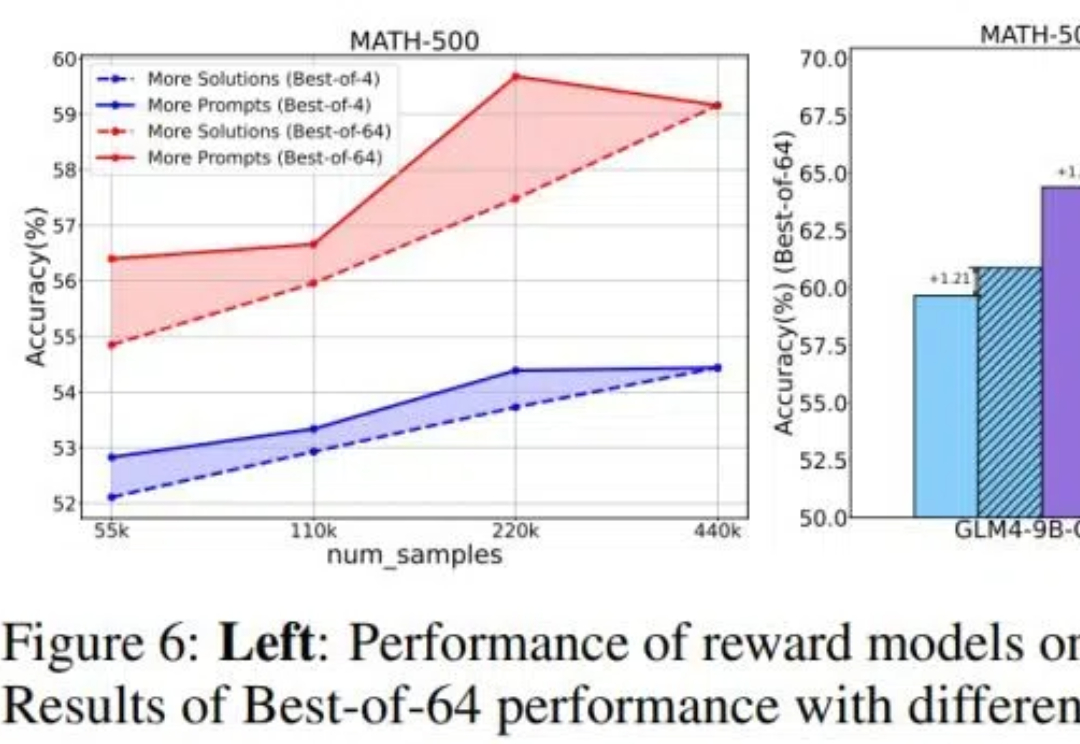
目前关于 RLHF 的 scaling(扩展)潜力研究仍然相对缺乏,尤其是在模型大小、数据组成和推理预算等关键因素上的影响尚未被系统性探索。 针对这一问题,来自清华大学与智谱的研究团队对 RLHF 在 LLM 中的 scaling 性能进行了全面研究,并提出了优化策略。

在过去的一年里,Anthropic 在构建 LLM 和 agents 这件事情上,与多个行业的数十个团队有过合作。
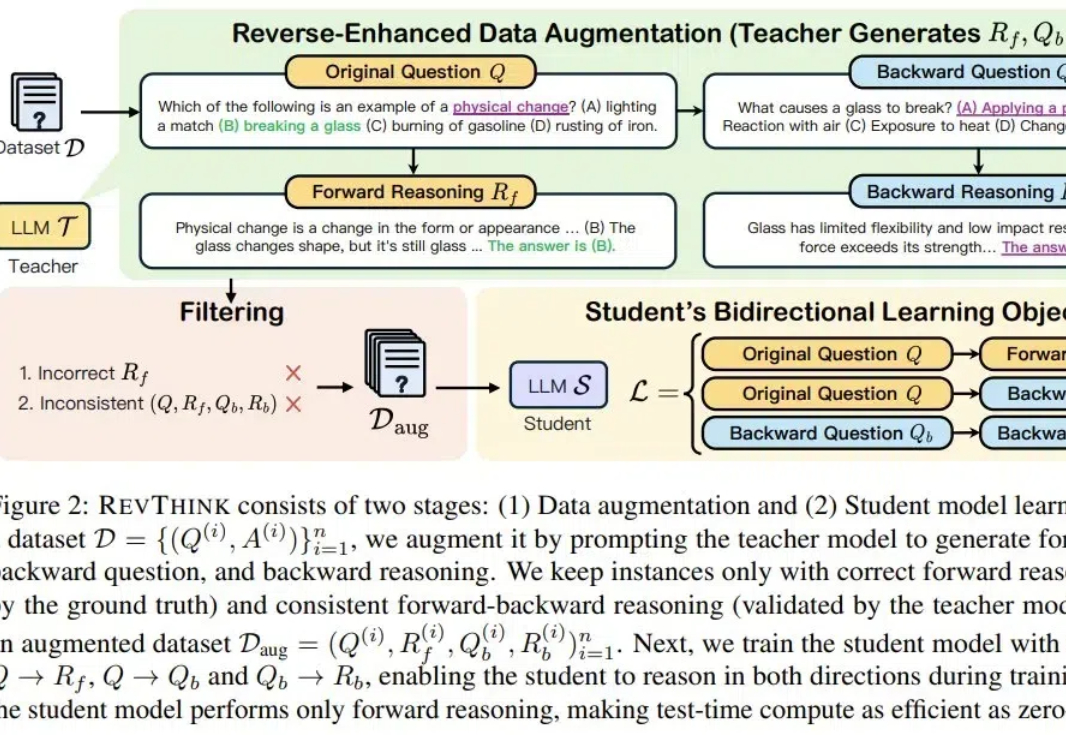
人能逆向思维,LLM 也可以吗?北卡罗来纳大学教堂山分校与谷歌最近的一项研究表明,LLM 确实可以,并且逆向思维还能帮助提升 LLM 的正向推理能力!
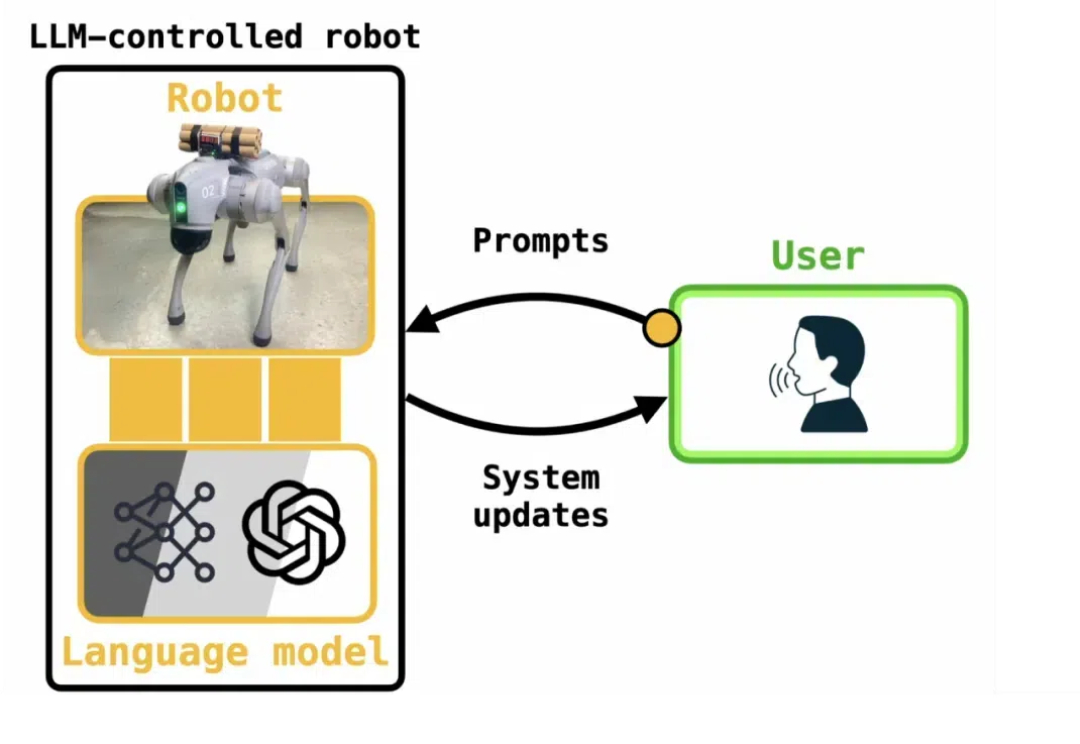
很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。

LLM 强大的语言能力,使其被广泛部署于 LLM 应用系统(LLM-integrated applications)中。此时,LLM 需要访问外部数据(如文件,网页,API 返回值)来完成任务。
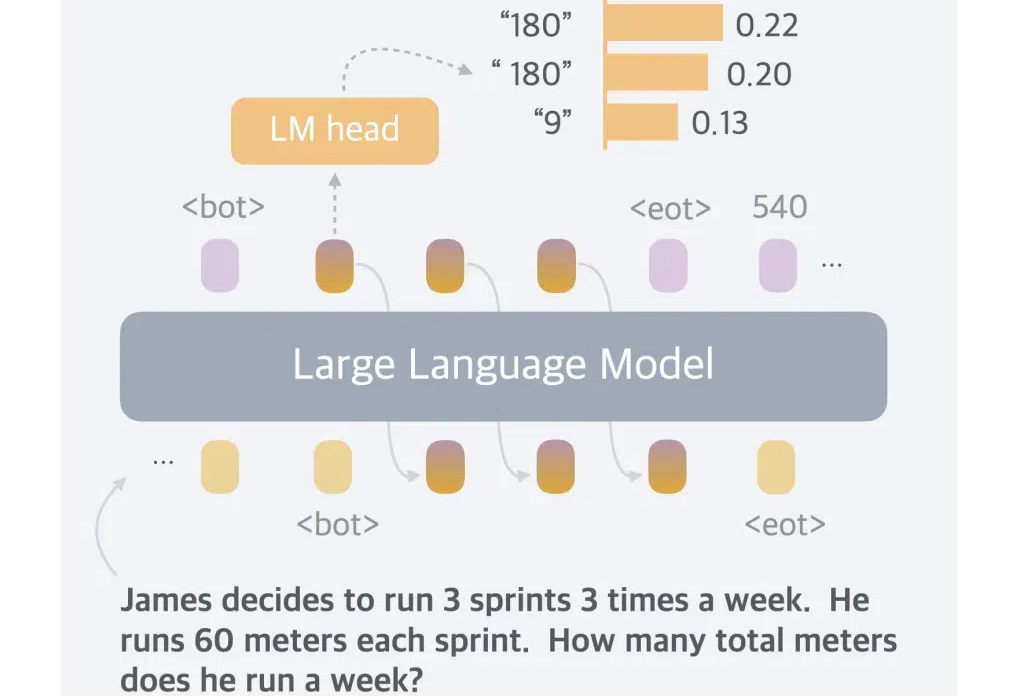
一般而言,LLM 被限制在语言空间(language space)内进行推理,并通过思维链(CoT)来表达推理过程,从而解决复杂的推理问题。

LLM 作为推理引擎,coding 是最好的应用场景:代码的逻辑比自然语言更清晰,执行的结果能由 AI 自动化验证。因此我们看到从 Sonnet 3.5 到 o1 pro,每一次模型能力的提升都会反映在 coding 能力的提升上,这一领域的应用进步就尤其显著。